本文遵循在云上设置和维护任何 Llama2 模型的最简单流程,本文采用7B模型,但你可以对于 13B 或 70B,请执行相同的步骤。分为两部分
第 1 部分:在亚马逊科技 AWS Sagemaker 上部署模型
第 2 部分:在应用程序中作为 API 运行

Llama 2是由 Meta 开发的预训练和微调的生成文本模型的集合。这些模型的参数范围从 70 亿到 700 亿不等,专为各种文本生成任务而设计。 Llama 2 系列中的模型,特别是 Llama-2-Chat 变体,针对对话用例进行了优化,在大多数基准测试中优于开源聊天模型。
1. 在 AWS Sagemaker 上部署
你需要拥有一个具有管理员权限的 AWS 账户,才能运行和部署 Llama-2–7B 模型,首次登录并前往 Amazon Sagemaker 控制台(尝试位于弗吉尼亚州北部的 us-east-1地区,Amazon Sagemaker 现有免费套餐)。
申请配额:
Amazon Sagemaker 中的资源并不总是被授予,因此应该快速检查一下
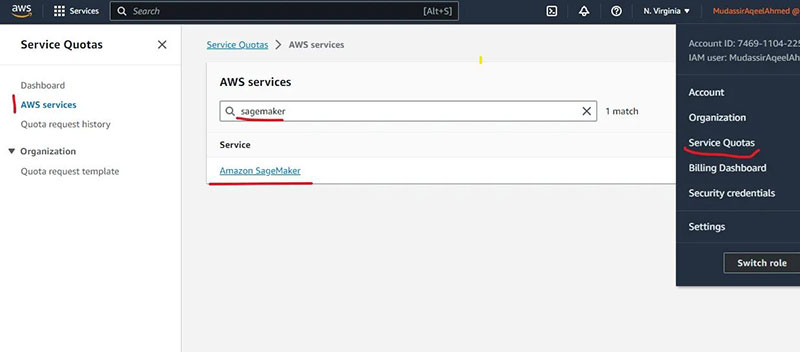
在 Sagemaker 中搜索这些服务配额,
域名总数
每个帐户允许的 Studio 用户配置文件的最大数量
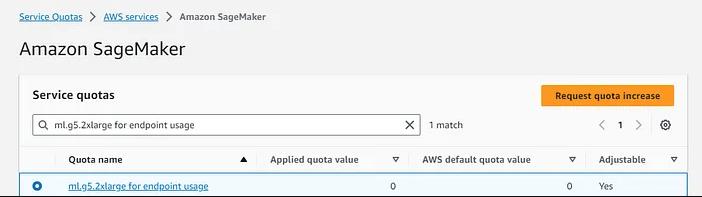
ml.g5.2xlarge 用于端点使用
每个帐户允许运行的 Studio 应用程序的最大数量
如果你需要请求增加配额的任何服务的应用配额值为 0,你可以在配额请求历史记录中跟踪请求,有时最多可能需要 2 天。
创建域:
第一个任务是创建一个域
选择快速设置
选择域名
你可以将用户配置文件名称保留为默认值,也可以根据需要进行更改
如果你没有角色,则需要创建一个角色。
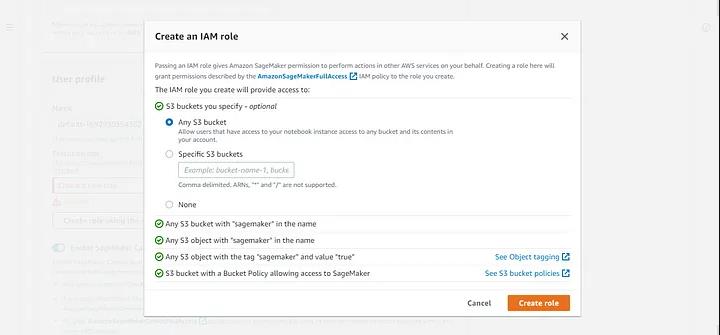
选择“任何 S3 存储桶”并点击创建。
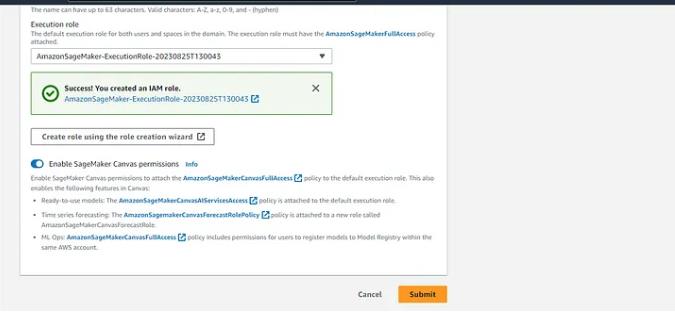
这就是它的样子,点击提交来创建域。
如果在创建域的过程中出现错误,则可能是由于用户权限或 VPC 配置问题造成的。
启动 Studio 并部署模型
成功创建域和用户配置文件后,启动 sagemaker studio

用户配置文件应该是你刚刚在域中创建的用户配置文件
Sagemaker 工作室主页
转到 Jumpstart 并搜索 Llama2–7b-chat
Llama2–7b-聊天模型页面。
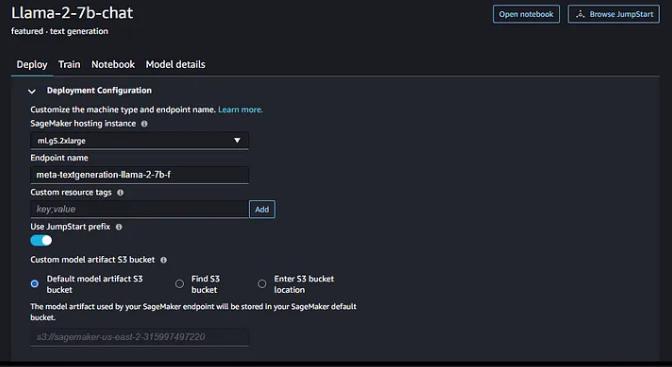
你可以将所有配置保留为默认值,ml.g5.2xlarge 是运行 llama2–7b 所需的最少模型,如果你让它运行,则成本为 1.515 美元/小时,36.36 美元/天:-)
单击“部署”将模型部署为端点,你将需要接受许可协议,部署将需要几分钟的时间。
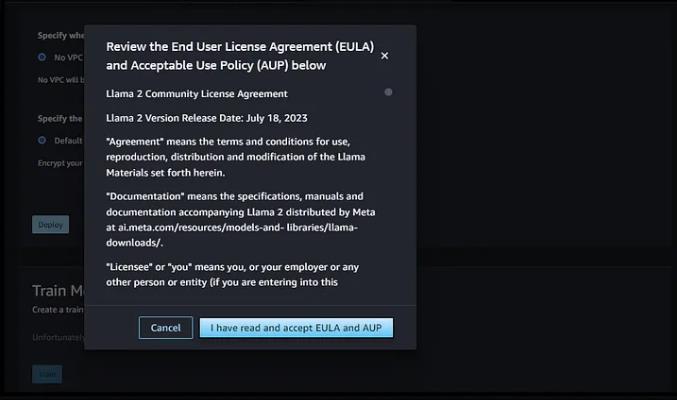
使用任何 llama2 模型之前的 meta 的 EULA
此时,你的模型已部署,你可以通过从 llama-7b-chat 模型页面打开笔记本来使用它运行推理(查询),并测试模型
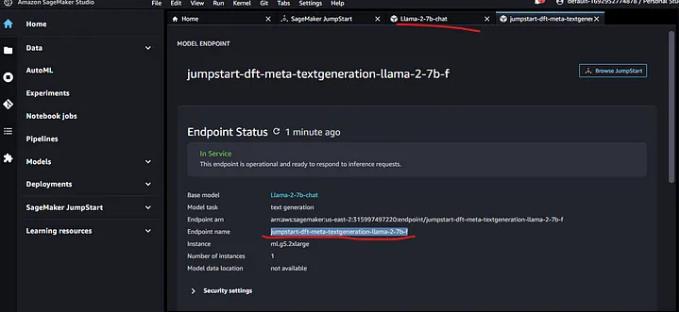
2. 作为API运行
为 AWS Lambda 创建 IAM 角色
前往 IAM >角色>创建角色
选择 AWS 服务和 lambda 服务,然后单击下一步。
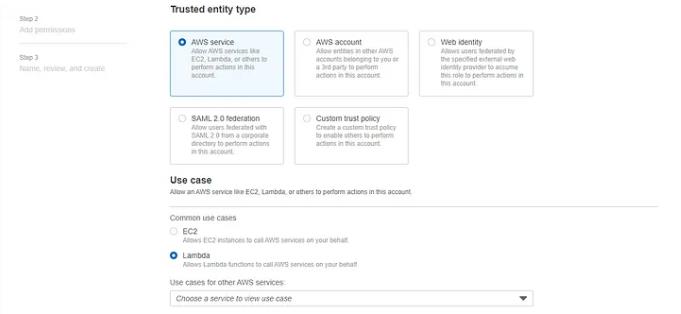
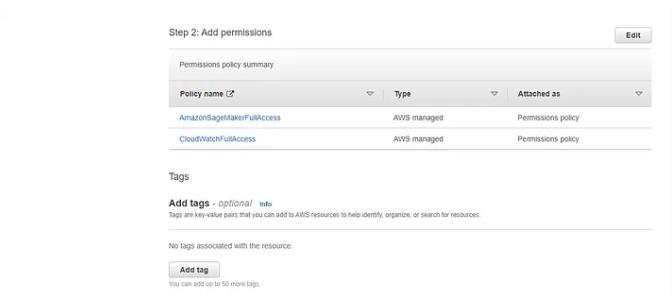
搜索这两个策略,然后单击下一步
CloudWatch完全访问
AmazonSageMakerFullAccess
对于手头的任务来说,这些可能有点过分了,但却消除了复杂性。
添加你的角色名称和描述(可选),并验证你选择的策略是否已作为权限添加到该角色。
单击创建角色进行创建。
创建 Lambda 函数
转到 Lambda >创建函数
1、从零开始
2、给它起个名字
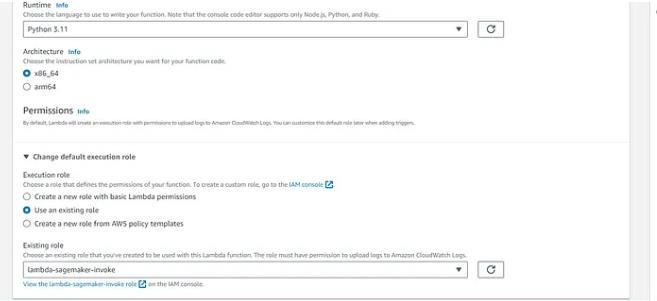
3、选择运行时为 Python 3.11
4、更改默认执行角色>选择现有角色,选择刚刚创建的角色
单击创建功能(将高级设置保留为默认值)。
已创建 lambda 函数
import os
import io
import boto3
import json
# grab environment variables
ENDPOINT_NAME = os.environ['ENDPOINT_NAME']
runtime= boto3.client('runtime.sagemaker')
def get_payload(query: str, prompt: str | None = None, max_new_tokens: int = 4000, top_p: int = 0.9, temperature: int = 0.01) -> dict:
if prompt:
inputs = [
{"role": "system", "content": prompt},
{"role": "user", "content": query}]
else:
inputs = [{"role": "user", "content": query}]
payload = {
"inputs": [inputs],
"parameters": {"max_new_tokens": max_new_tokens, "top_p": top_p, "temperature": temperature}
}
return payload
def lambda_handler(event, context):
query = event["query"]
if "prompt" in event:
prompt = event["prompt"]
payload = get_payload(query, prompt)
else:
payload = get_payload(query)
response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME,
ContentType='application/json',
Body=json.dumps(payload),
CustomAttributes="accept_eula=true")
result = json.loads(response['Body'].read().decode())[0]
output = result['generation']['content']
print(result)
return {
"statusCode": 200,
"body": output
} |
将此代码复制到你的 lambda 函数,然后转到配置
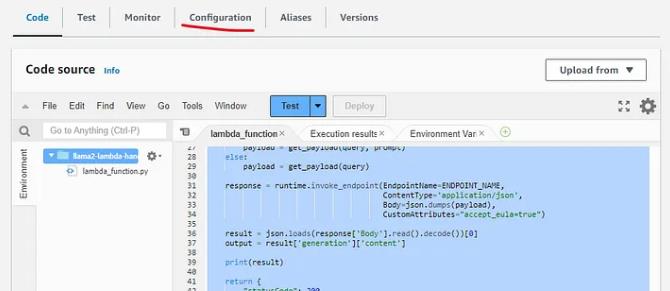
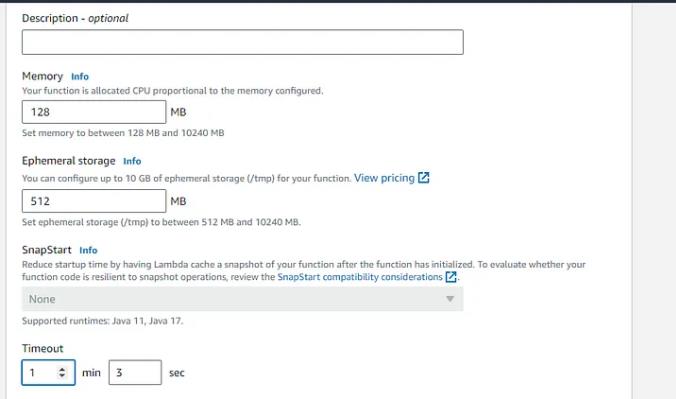
在常规配置上,单击编辑并将超时从 3 秒更改为 1 分 3 秒(最长为 15 分钟,但我们不需要那么多)
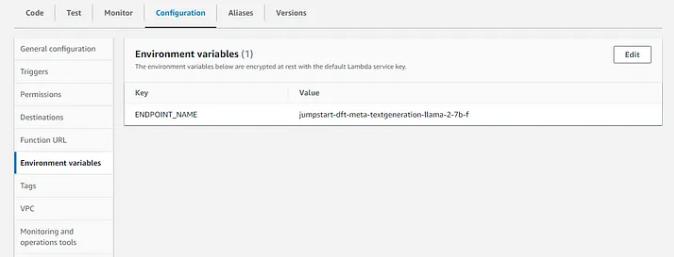
编辑环境变量并添加你的 ENDPOINT_NAME(位于部署页面上)
你可以在 Sagemaker > 上再次找到它推理>端点(或者从工作室部署页面,如果你仍在运行)
之后,你可以部署 lambda 并运行快速测试,
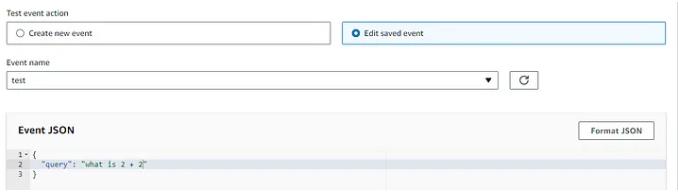
如果一切顺利,这应该是你的输出响应
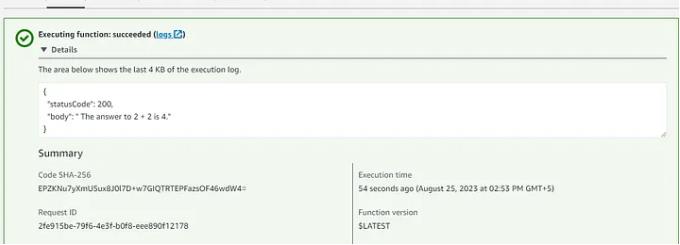
带有 API 网关的 Rest API
转到 API 网关,从 API >休息 API >构建>新API>创建API
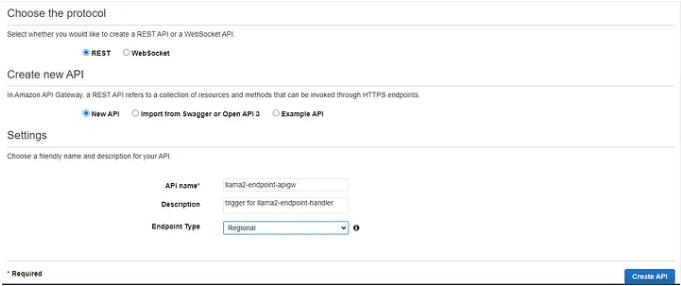
API Gateway Rest API创建控制台
转到“操作”>创建方法>邮政
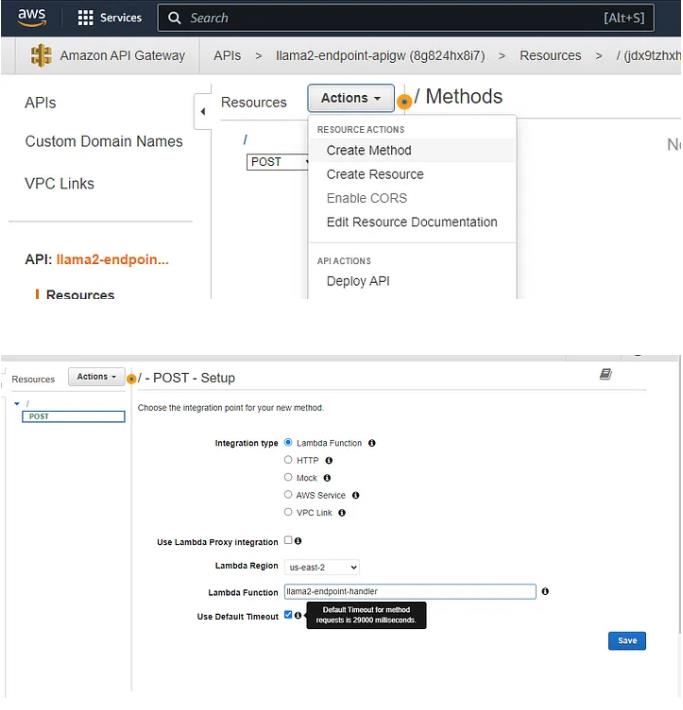
单击“保存”
最后转到操作> API 操作 >部署API
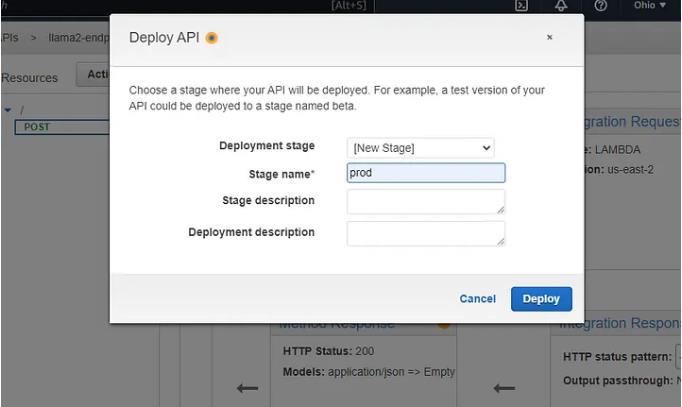
与舞台一起部署
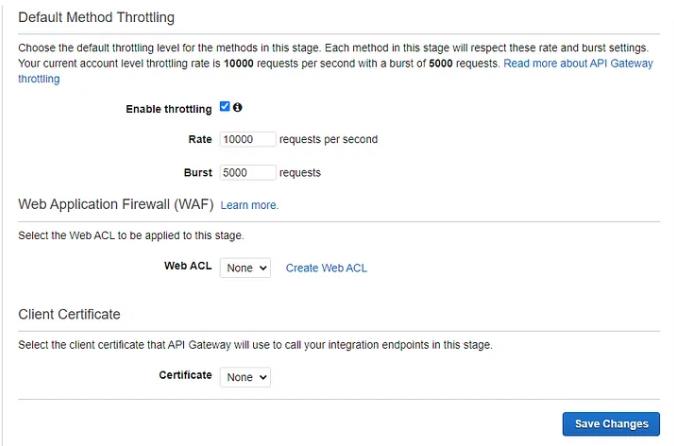
API部署阶段
保存更改,向上滚动以复制调用 URL(你可以在触发器部分的 lambda 函数上找到它),然后就可以了。
| import requests def llama_chain(query): api_url = 'https://n0f3c5se9l.execute-api.us-east-1.amazonaws.com/prod/' # Replace this with your apigw URL prompt = "You are an expert mathematician given a user query do a step by step reasoning, and then generate an answer" json = {"query": query, "prompt": prompt} r = requests.post(api_url, json = json) answer = r.json()["body"].strip() return answer llama_chain("what is 2 + 2") |
你可以运行此函数来调用你的API网关(此JSON中的提示字段是可选的)。如果你不再使用端点,请从 Sagemaker studio 部署页面或 Sagemaker > 中删除该端点。推理>端点/模型/端点配置
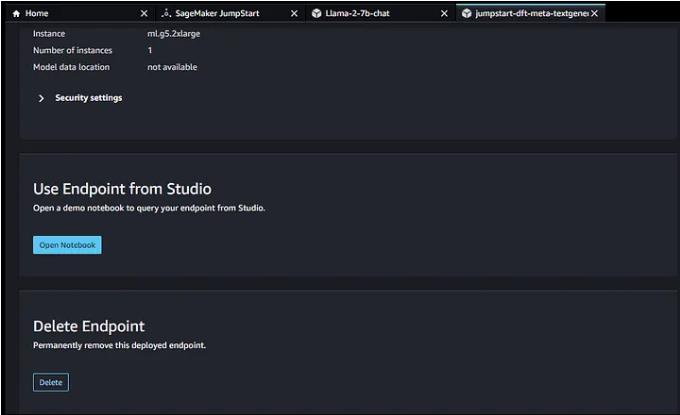
Sagemaker Studio llama2 部署页面
如果你遇到任何问题,请评论出来。我计划使用 langchain 和 pinecone/chroma 在此 API 之上为 RAG(与你的数据聊天)创建一个应用程序。